Voiceprint (Voice Cloning)
Basic Introduction
Voiceprint technology refers to the use of artificial intelligence models to generate speech audio that matches specific sound characteristics. By combining voiceprint information with text content, it can generate speech with specific timbre, intonation, and speech rate. Voiceprint technology is widely used in fields such as personalized text-to-speech, voice assistants, and intelligent customer service.
Currently, most text-to-speech models available on Model Plaza support voiceprints, but each model uses voiceprints in different ways, mainly including the following:
- Built-in voiceprints
- Directly using recordings as voiceprints
- Using recordings with corresponding text content as voiceprints
- Using
.ptformat voiceprint files
1. Built-in Voiceprints
Some models do not support custom voiceprints; they have a few built-in voiceprint options, and users can directly use these models for text-to-speech. For example, Spark-TTS-0.5B allows selecting built-in male and female voiceprints.
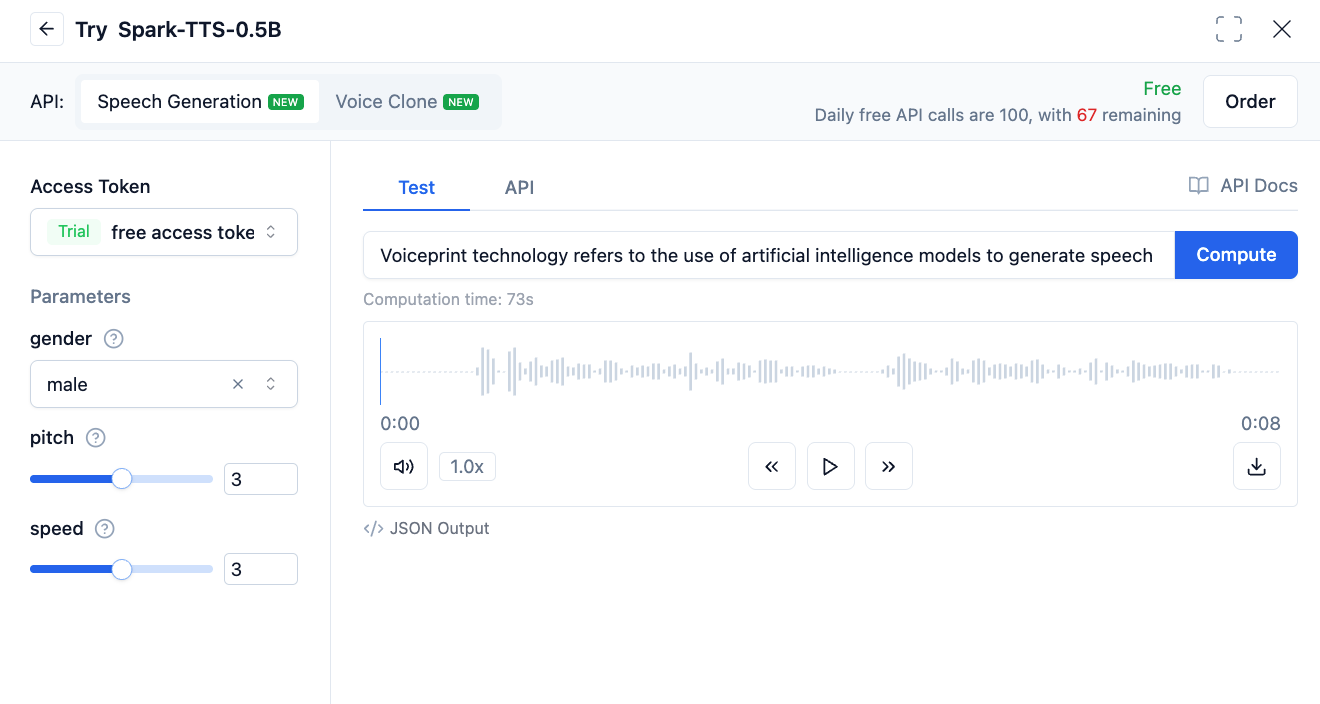
2. Directly Using Recordings as Voiceprints
IndexTTS-1.5 uses recordings as voiceprint information. Users only need to upload an audio file, and the model will automatically extract sound features from the audio for text-to-speech.
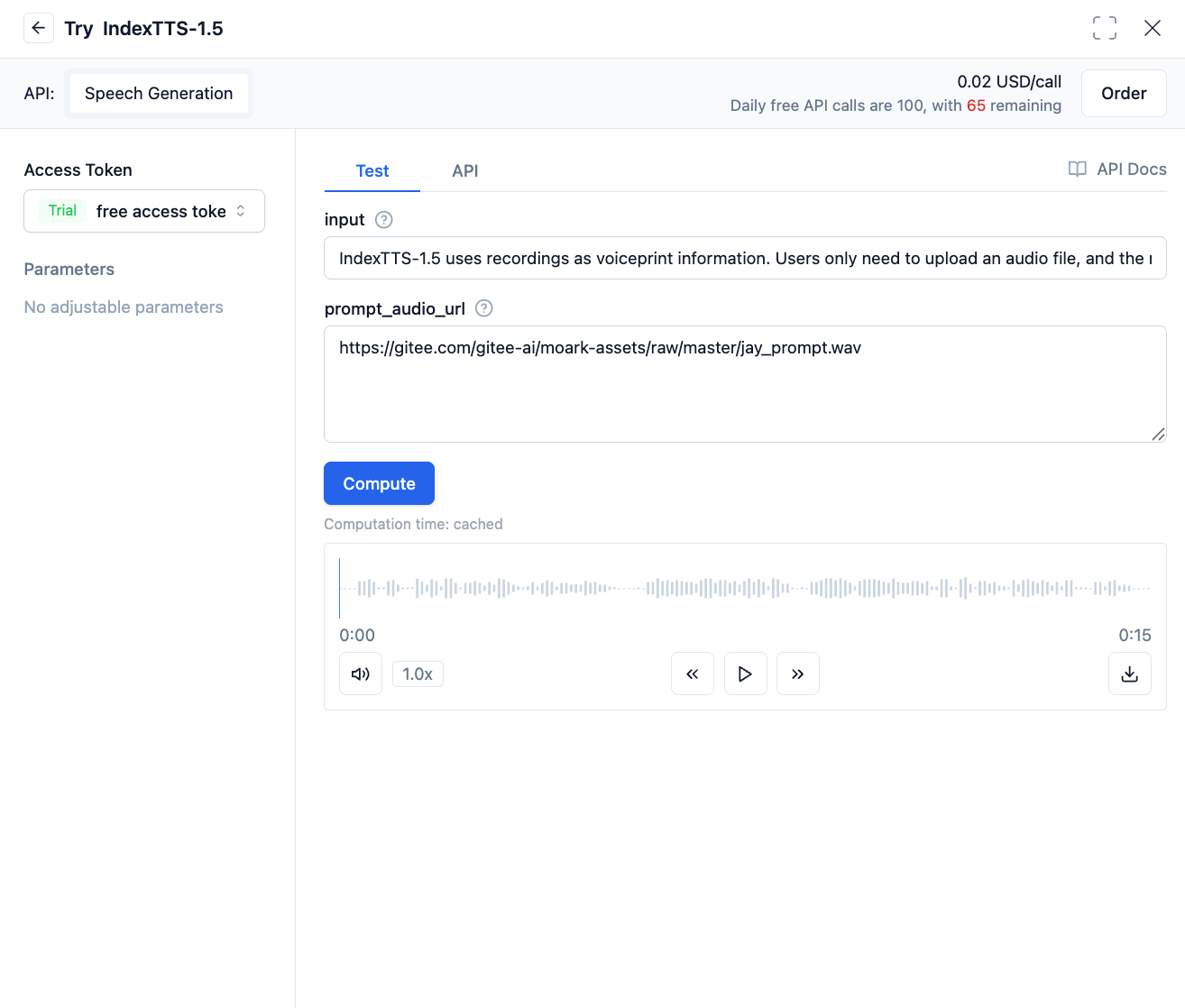
3. Using Recordings with Corresponding Text as Voiceprints
As shown in the figure below, the voiceprint requirements for models F5-TTS, CosyVoice2-0.5B, and Step-Audio-TTS-3B all require recording a sample audio in WAV format, along with the text content corresponding to the recording as voiceprint information. Please use recording software to record audio with clear articulation. The recommended duration is 5-15 seconds, and the file format is .wav. It is advisable that the file size is not too large.
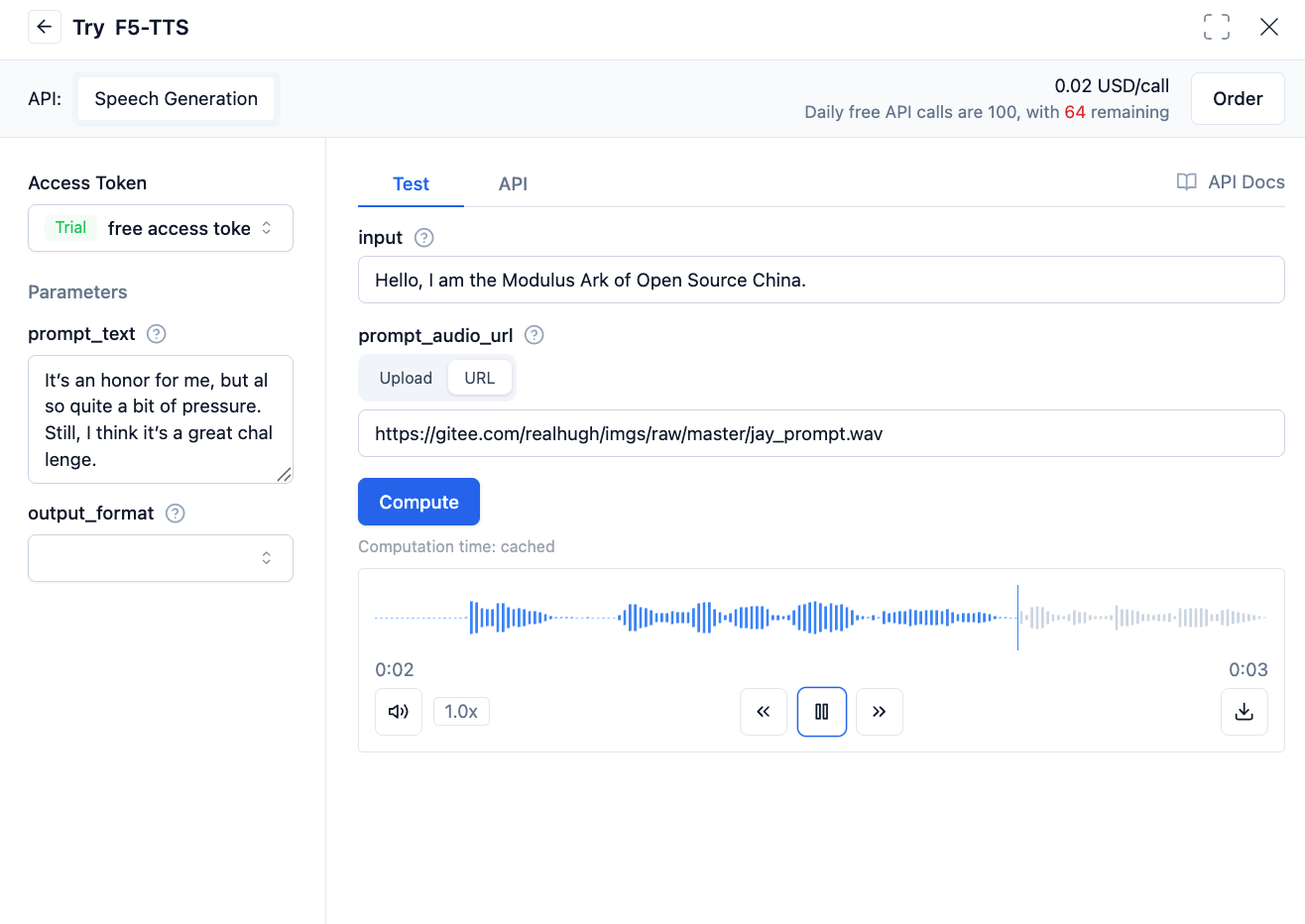
4. Using .pt Format Voiceprint Files
You only need to configure voice_url in the parameter settings of the speech generation model, passing the .pt format voiceprint file to the model via a URL, and you can generate audio that matches the sound characteristics in the file. It mainly includes the following key steps:
- Create a .pt format voiceprint file, which can be converted from an audio file. Different models require different voiceprint files:
- For
CosyVoice-300Mandfish-speech-1.2-sftmodels, you can use the voiceprint file interface provided by the platform. - For
ChatTTSmodel, you can use the ChatTTS voice cloning tool at http://region-9.autodl.pro:41137/ (this page is currently inaccessible, and the official no longer provides direct services for generating pt files).
-
Store the created .pt format voiceprint file in a publicly downloadable address, such as your
Giteecode repository. -
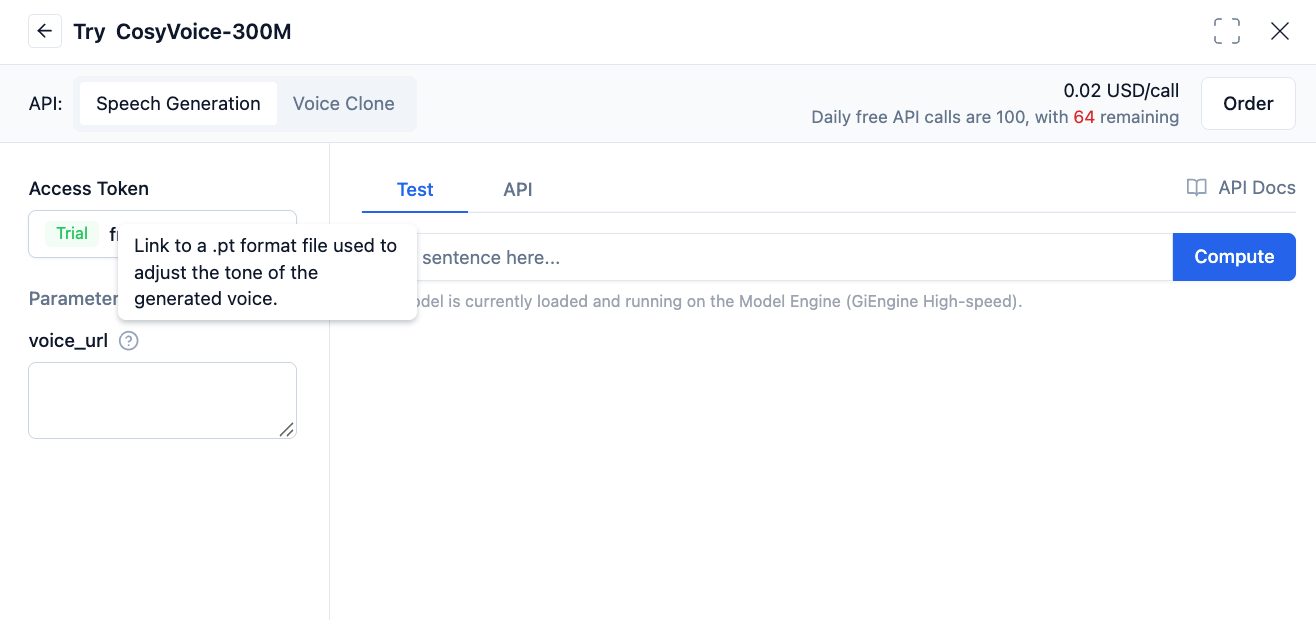
Copy the download address to the
voice_urlparameter in the model as shown in the figure below. Finally, enter the text and run it to generate a sound with the same timbre as the file.
Step 1: Create .pt Format Voiceprint Files
1.1 Create Audio Files
Use recording software to record audio with clear articulation. The recommended duration is 5-15 seconds, and the file format is .mp3 or .m4a. It is advisable that the file size is not too large.
1.2 Generate Voiceprint Files for CosyVoice-300M and fish-speech-1.2-sft Models
Upload the audio file to the voice feature extraction interface provided by the platform. The following is a detailed description of the interface:
Function Description
This interface is used to process audio files and extract key audio features.
Notes
- File size limit: less than 5 M
- Supported audio formats: .mp3 or .m4a
- This interface can extract key features from audio for subsequent processing and analysis.
Calling Method
HTTPS call
POST https://api.moark.ai/v1/audio/voice-feature-extraction
Request Parameters
| Parameter Position | Name | Type | Required | Description |
|---|---|---|---|---|
| Header | Authorization | string | Yes | Access token, which can be generated and obtained in Workbench -> Settings -> Access Tokens. Format: "Bearer access_token", Example: "Bearer t-g1044qeGEDXTB6NDJOGV4JQCYDGHRBARFTGT1234" |
| form-data | file | file | Yes | Voice content. Note: Content-Type is application/octet-stream, and the example value is a binary file. |
| form-data | prompt_text | string | Yes | Prompt content. Note: Text description consistent with the recording content. |
| form-data | model | string | Yes | Model name: CosyVoice-300M |
Return Parameters
When the HTTP status code is 200, it indicates success. Returns the file binary stream.
cURL Example
cURL
--location --request POST 'https://api.moark.ai/v1/audio/voice-feature-extraction'
--header 'Authorization: Bearer Enter your access token '
--form 'model="CosyVoice-300M"'
--form 'file=@"Upload .mp3 or .m4a format files"'
--form 'prompt_text="Text description consistent with the recording content"'
Example of Request Using APIfox Interface Tool
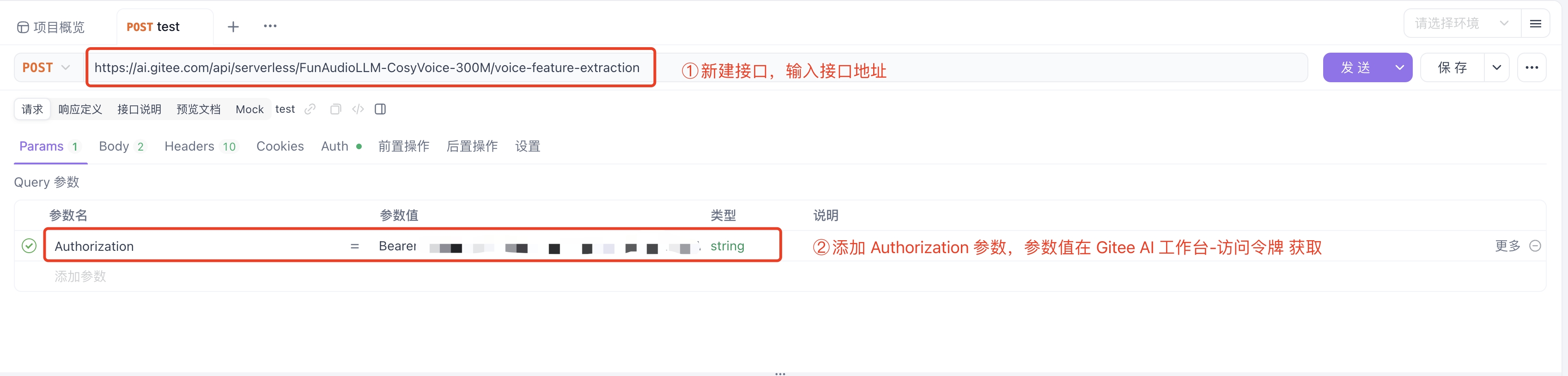
-
Create a new interface and enter the interface address.
-
Add the Authorization parameter. The parameter value can be obtained from MoArk Workbench - Access Tokens.
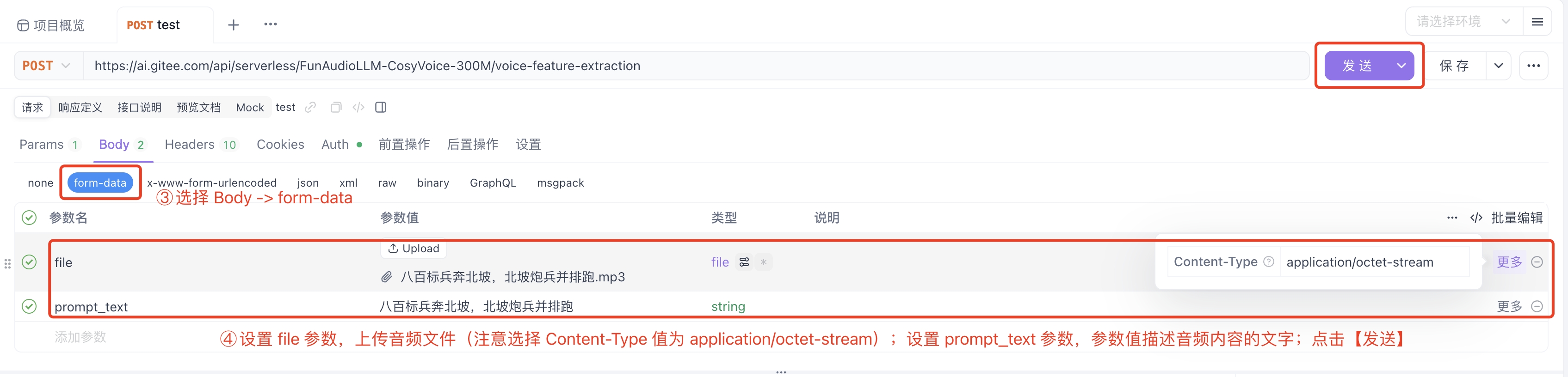
-
Select Body -> form-data.
-
Add the file parameter and upload the audio file; add the prompt_text parameter with a value that is the text description consistent with the recording content. After completion, click Send.
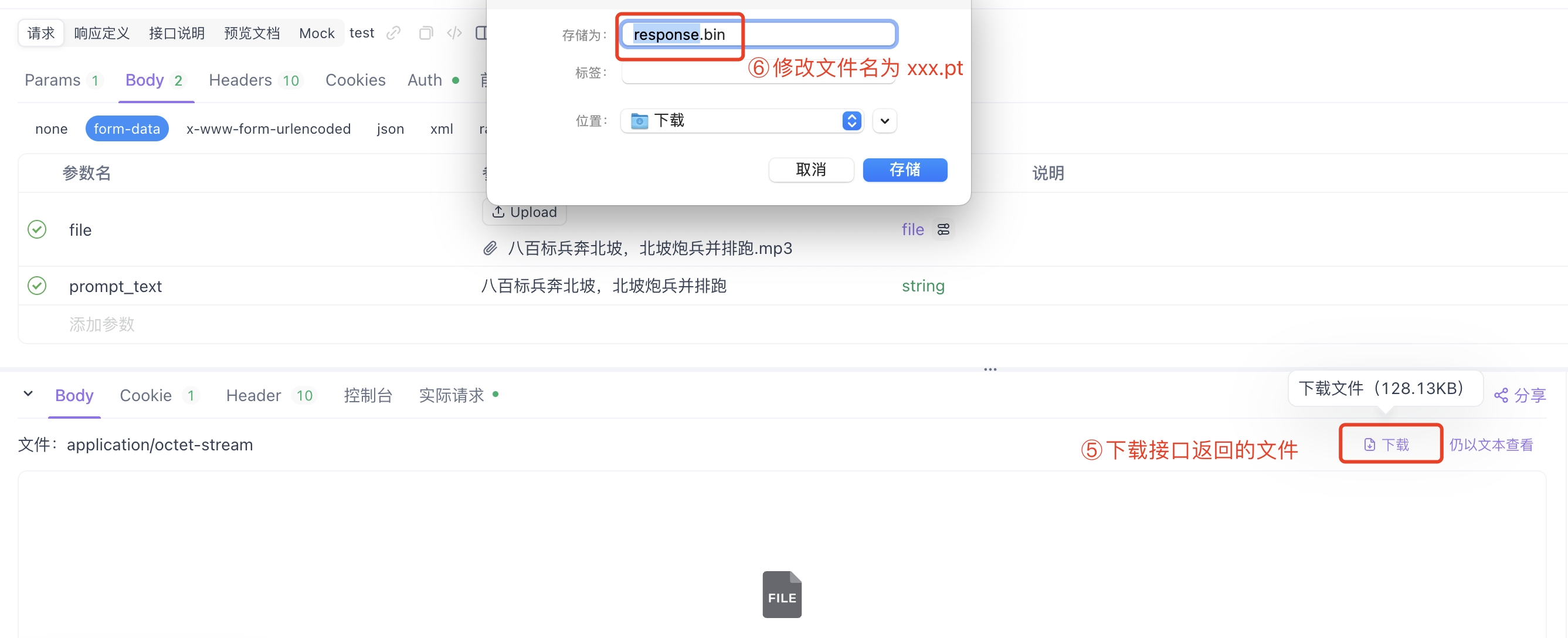
-
After a successful request, download the file returned by the interface and rename it to xxxx.pt.
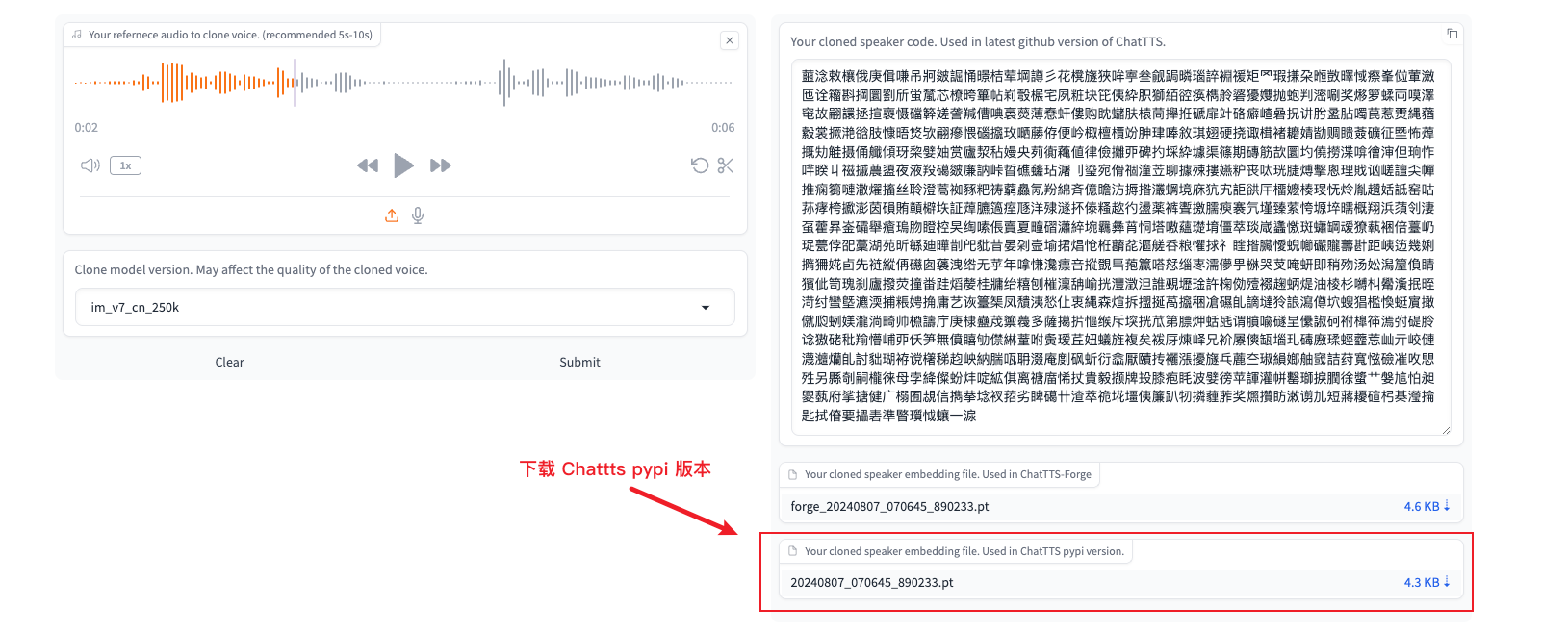
1.3 Generate Voiceprint Files for ChatTTS Model
- Visit the ChatTTS voice cloning tool at http://region-9.autodl.pro:41137/
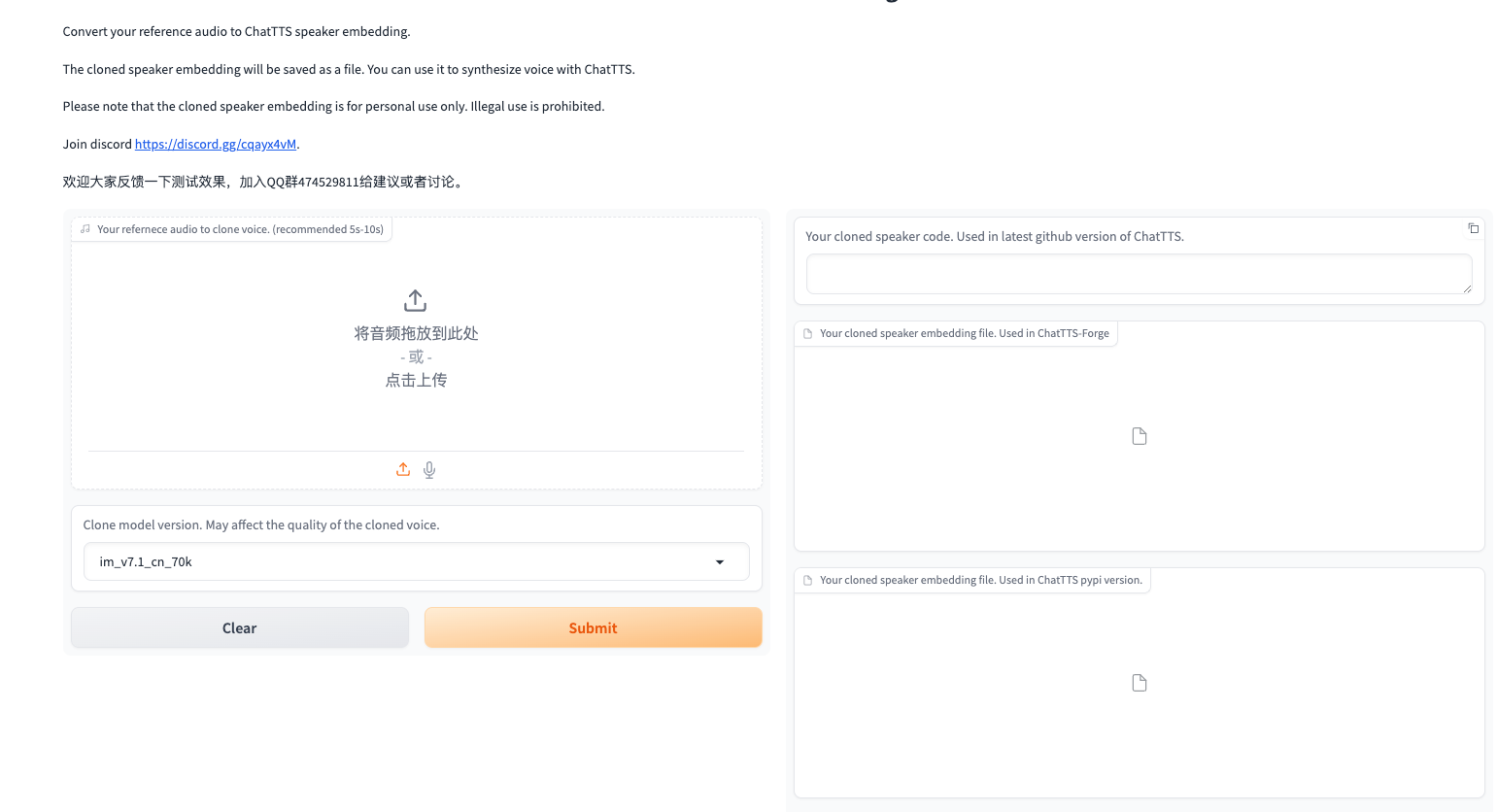
-
Upload/record audio and click submit. Wait for generation.
-
After successful generation, download the pt file for the ChatTTS pypi version.
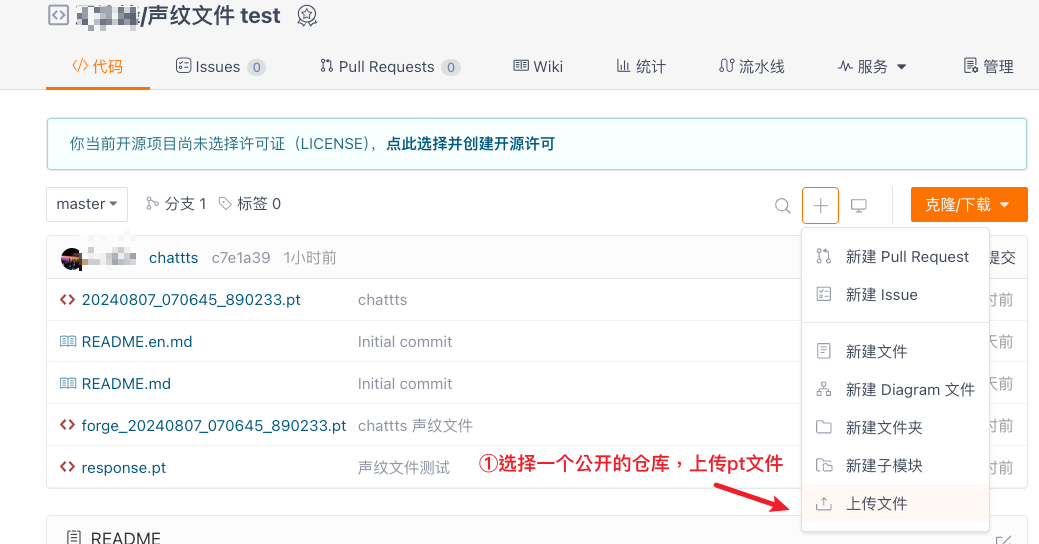
Step 2: Upload Voiceprint File and Obtain Download URL
The voice_url parameter of the speech generation model needs to read the voiceprint file, so we need to upload the voiceprint file to a network disk or other downloadable public space, obtain the file download URL, and configure it to the voice_url parameter of the voice model.
It is recommended that you create or select a public repository on Gitee and upload the .pt file to the repository. Find the uploaded file in the Gitee repository, click the file name to enter the download page, right-click to download and copy the download address, as shown below:


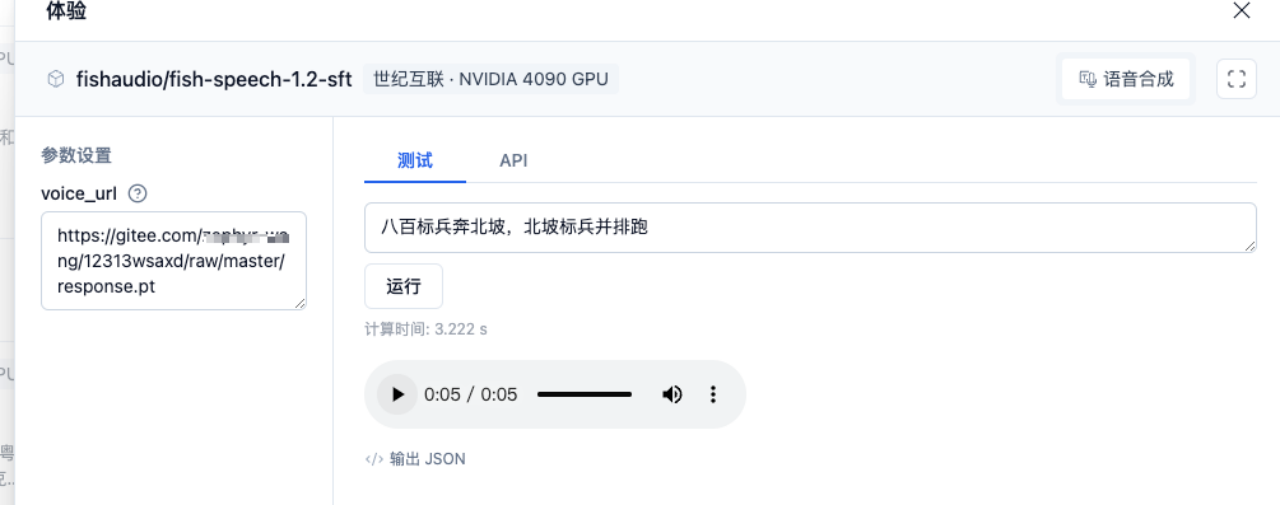
Step 3: Paste the Address in Model Parameters
According to the type of pt file you generated, select CosyVoice-300M, ChatTTS, or fish-speech-1.2-sft. Paste the voiceprint file download URL into the voice_url parameter, enter text, and run. You can generate a sound with the same timbre as the voiceprint.
You can create voiceprint file URLs for personal or specific voices, experience the generation effects of different models, and integrate the model API into your business to implement various interesting and useful applications.