Text-to-Speech
Basic Introduction
Speech generation refers to the technology of generating speech audio through artificial intelligence models. Its core task is to convert text into audible sounds, usually in the form of human speech. Speech generation models can simulate human speech characteristics, including timbre, intonation, speech rate, etc., making the generated speech sound more natural and realistic.
Model List
The speech generation models currently available on the Model Plaza include:
Loading Serverless API service list...
Note that the usage of each model may vary slightly; please refer to the respective model's experience page for details.
Online Experience
Taking the F5-TTS model as an example, the model takes text content as input and outputs the corresponding audio file. Users can use the model by entering text.
As shown in the figure below:
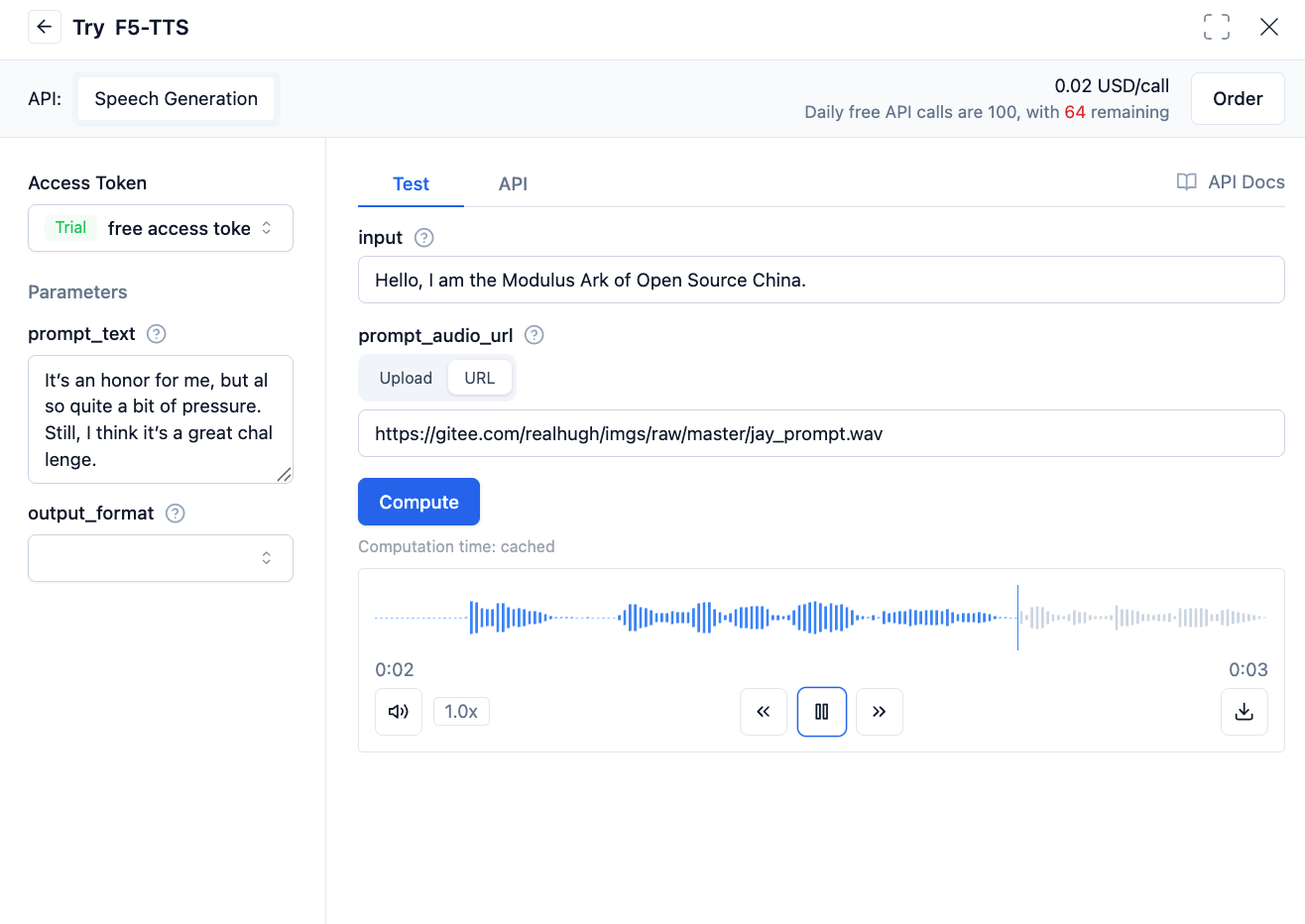
Additionally, you can customize the voiceprint. F5-TTS requires recording a sample audio in WAV format along with the corresponding text content of the recording as voiceprint information.
For instructions on using voiceprints, please refer to Voiceprint Usage Guide.
Example Code
The following is an example code for using the Python SDK to call the speech generation model:
from openai import OpenAI
client = OpenAI(
base_url="https://api.moark.ai/v1",
api_key="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", # Please replace with your token
)
response = client.audio.speech.create(
input="Hello, I am the Model Power Ark of Open Source China.",
model="F5-TTS",
extra_body={
"prompt_audio_url": "https://gitee.com/realhugh/imgs/raw/master/jay_prompt.wav",
"prompt_text": "To me, it is a kind of honor, but it is also a lot of pressure. However, I think it is a very good challenge.",
},
voice="alloy",
)