Speech Recognition
Basic Introduction
Speech recognition is a technology that converts speech signals into text. Its core task is to transform human speech input into textual information that machines can understand and process. Speech recognition technology is widely applied in areas such as voice assistants, automatic subtitle generation, and voice search.
Model List
The speech recognition models currently available on the Model Plaza are listed in the table below. These models basically support multilingual speech recognition and can accurately convert speech in different languages into text.
Loading Serverless API service list...
Online Experience
Taking the SenseVoiceSmall model as an example, the model takes audio files as input and outputs corresponding text content. Users can use the model by uploading audio files or providing audio URLs. SenseVoiceSmall supports speech recognition in up to 5 languages, including Chinese, English, Cantonese, Japanese, and Korean.
As shown in the figure below:
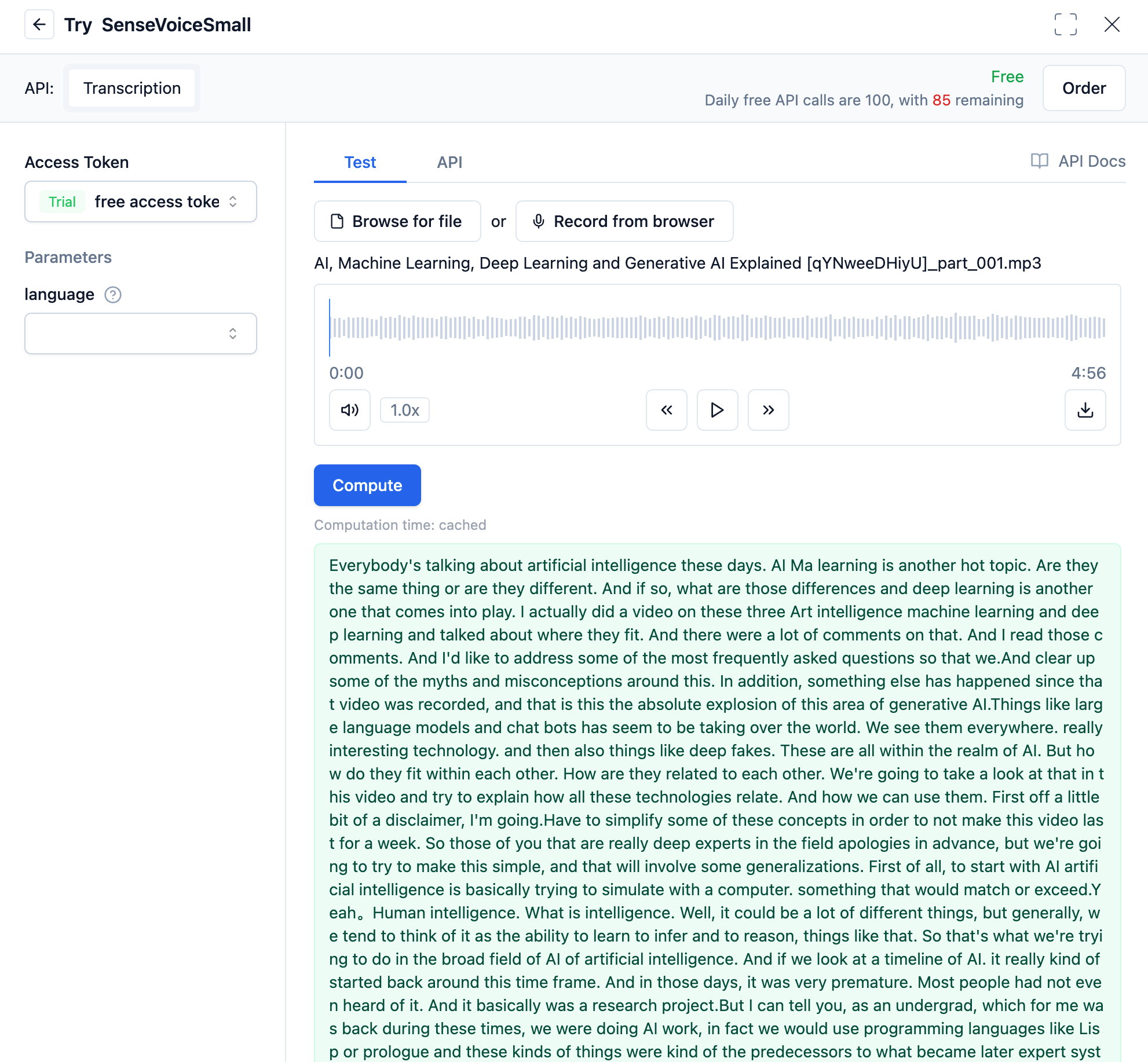
Example Code
The following is an example code for calling the speech recognition model using Python:
import requests
from requests_toolbelt import MultipartEncoder
import os
API_URL = "https://api.moark.ai/v1/audio/transcriptions"
API_TOKEN = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" # Please replace with your token
headers = {
"Authorization": f"Bearer {API_TOKEN}"
}
def query(payload):
fields = [
("model", payload["model"]), # Model name
("language", payload["language"]),
("file", (os.path.basename(payload["file"]), open(payload["file"], "rb"), "audio/wav")),
]
encoder = MultipartEncoder(fields)
headers["Content-Type"] = encoder.content_type
response = requests.post(API_URL, headers=headers, data=encoder)
return response.json()
output = query({
"model": "SenseVoiceSmall",
"language": "zh"
})
print(output)