Model Hub Overview
The Model Hub offers developers an effortless way to access diverse AI models without managing underlying hardware or infrastructure. Interact with MoArk's full suite of model services through simple HTTP requests.
Experience Model Services
You can explore our selected models on Model Hub and experience different model outputs for free. Additionally, you can call the API to integrate these models into your applications.
Currently, we have deployed more than 100 models across various categories. Here's a list of the largest language models:
Loading Serverless API service list...
More model API services are gradually added...
Purchase Model Resource Packs
Purchase Process:
- Online Experience Models: Visit Model Hub to explore the list of deployed models. You can experience the models for free.
- Purchase Resource Pack: In the Model Hub, click Purchase Full Model Resource Pack to purchase a resource pack for yourself or your organization.
- Create Order and Payment: After completing the payment, you can experience all the models on Model Hub or call the API to integrate these models into your applications.
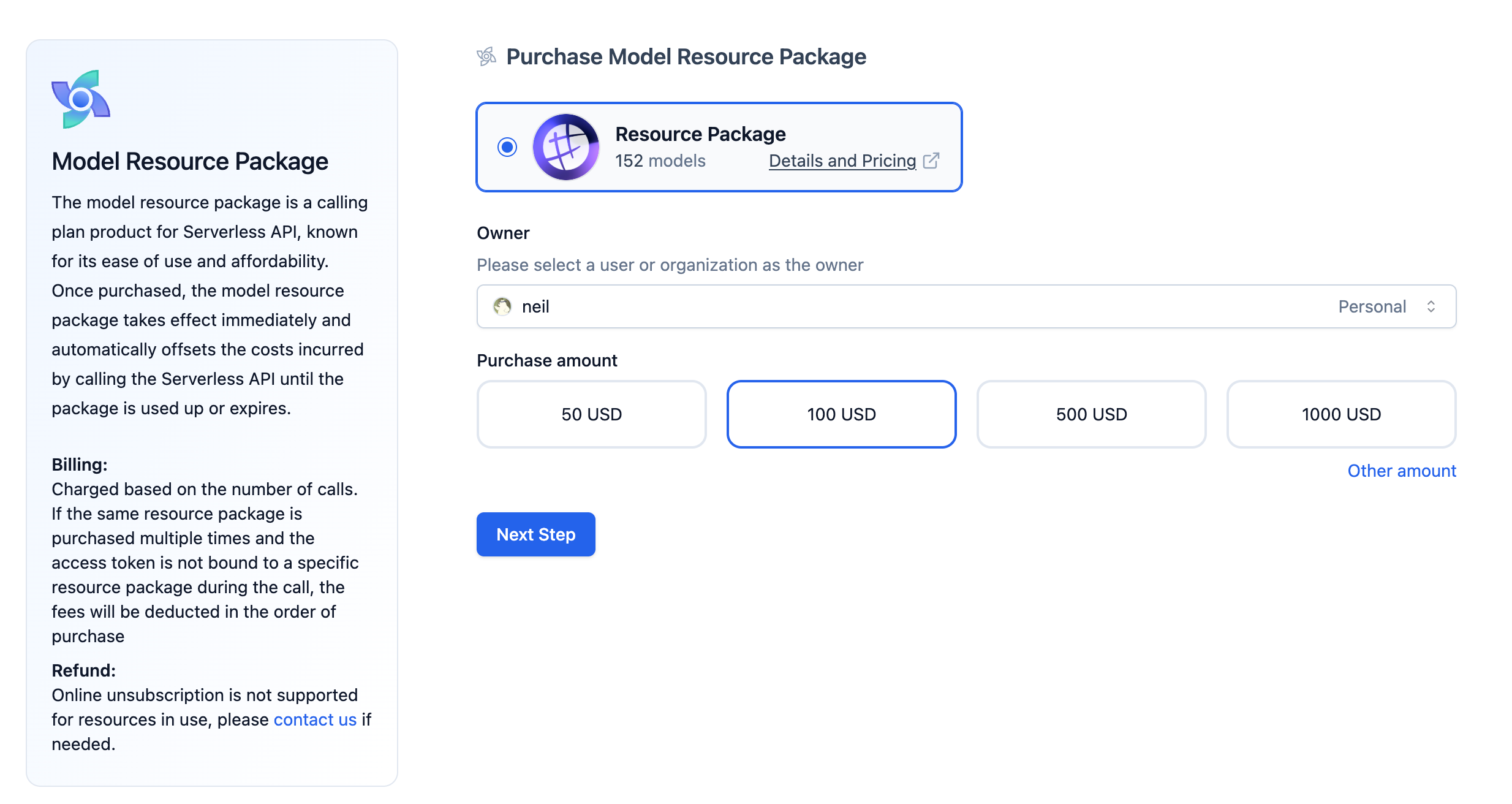
Billing Information:
- Billing Rules: Support two billing methods: by call count and by
tokens. You can choose the one that suits your needs. If you have purchased multiple resource packs and the access token is not bound to a specific resource pack, the system will deduct according to the order of purchase. - Cancellation Rules: Models in use do not support refunds.
For more information on purchasing model resource packs, please visit Purchase Model Resource Packs.
Local API call for inference (to be changed when there is an operational interface)
If you want to perform model inference through the Serverless API, please follow the steps below:
-
Create Access Token: You need to log in to your account, go to Dashboard -> Settings -> Access Tokens, and create a token that authorizes access to the selected resources; if you want to bind a specific resource package to an "access token," you can also create an "access token" that supports access to "partial resources."
-
Call Serverless API: In the AI Model Plaza, select the purchased model resource package.
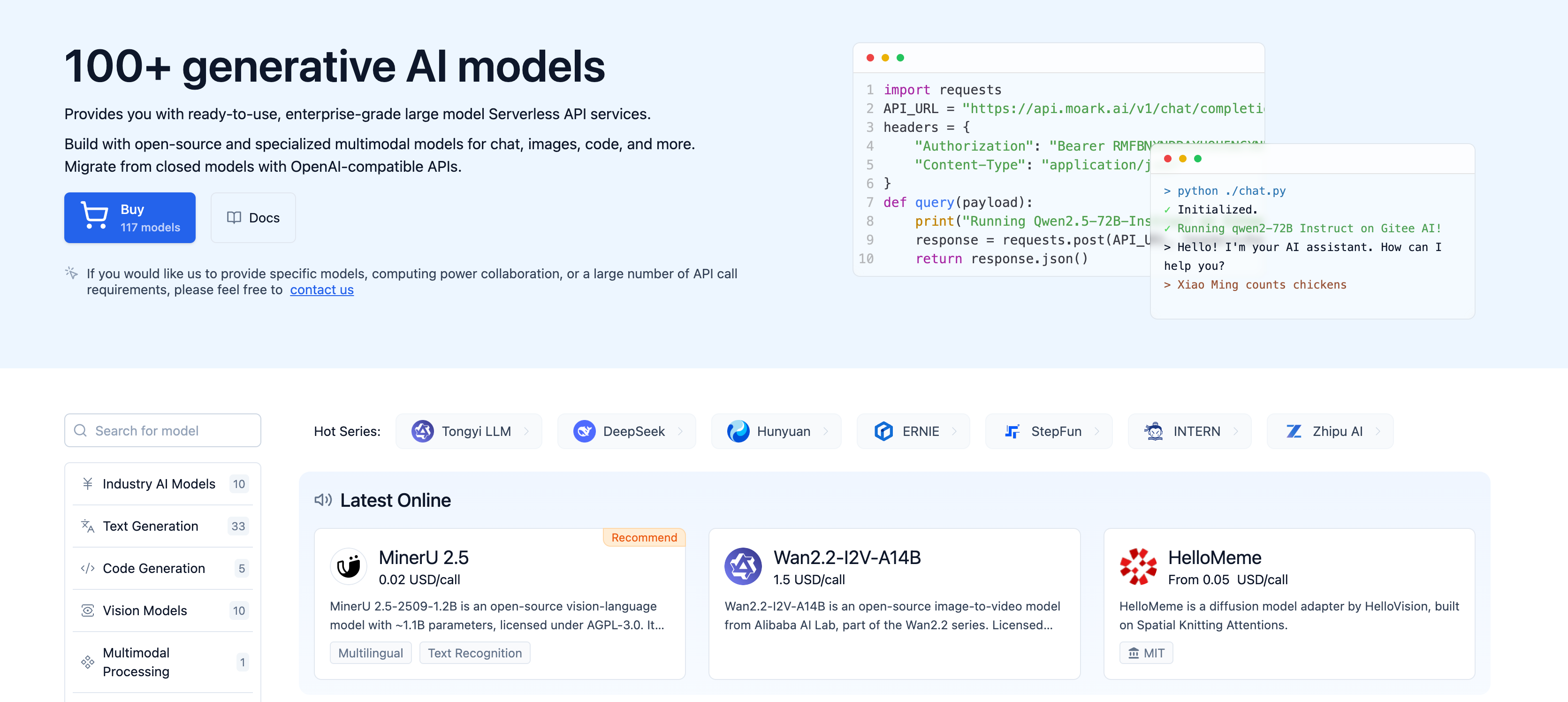
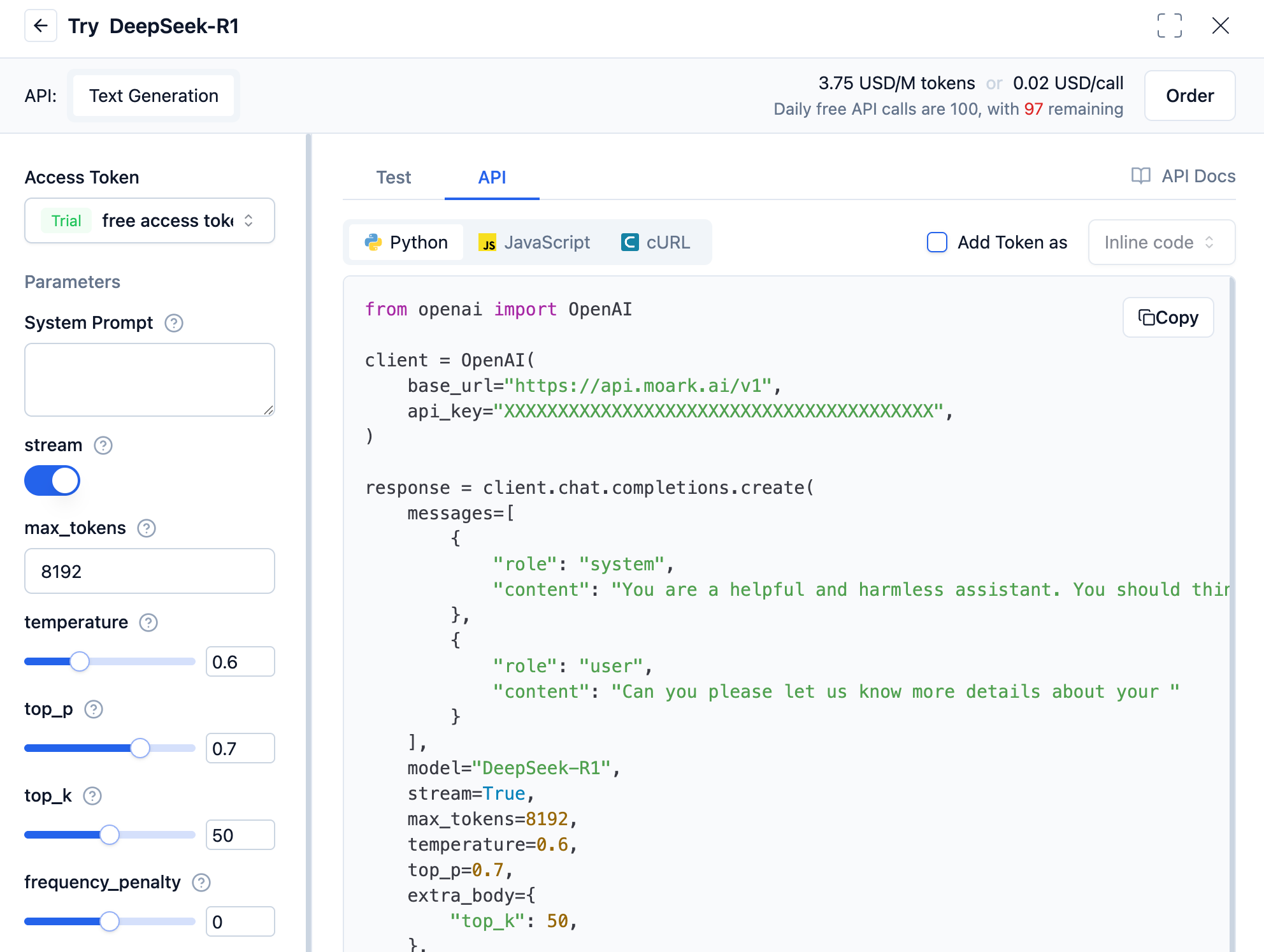
-
Local API invocation for inference: It can be tested normally through the widget, and you can choose to call in "API" form, selecting the corresponding programming language or tool, such as Python. Check "Add token" to copy the corresponding code for local execution. Currently, we only provide examples in Python/JavaScript/cURL; other languages can refer to these examples for writing.
Failover Mechanism
Our API features a built-in failover mechanism to ensure service continuity and stability. If a model inference fails, the system automatically reroutes the request to another available compute resource.
How to Use: Enable the failover mechanism by adding the request header X-Failover-Enabled: true. Set it to false to disable failover and receive an immediate error upon failure.
- When failover is enabled, if the primary compute resource fails, the system will automatically switch to an available one. Billing will be calculated based on the compute resource of the last successful call, and the cost will be deducted from your resource package. You can view the complete call chain in your "Usage Logs." If you do not agree with this billing method, please disable the failover mechanism.
- If the
X-Failover-Enabledheader is not included in the request, the system will default to enabling the failover mechanism for models that support it.